hist¶
The hist function allows histogram visualizing DataFrame data. At a
minimum, the hist function requires the following keywords:
df: a pandas DataFramex: the name of the DataFrame column containing the x-axis data
The y-axis will display the histogram counts for the specified data set.
Other optional keywords for this function are described in Keyword Arguments.
Setup¶
Imports¶
In [1]:
%load_ext autoreload
%autoreload 2
%matplotlib inline
import fivecentplots as fcp
import pandas as pd
import numpy as np
import os, sys, pdb
osjoin = os.path.join
st = pdb.set_trace
Sample data¶
In [2]:
df = pd.read_csv(osjoin(os.path.dirname(fcp.__file__), 'tests', 'fake_data_box.csv'))
df.head()
Out[2]:
| Batch | Sample | Region | Value | ID | |
|---|---|---|---|---|---|
| 0 | 101 | 1 | Alpha123 | 3.5 | ID701223A |
| 1 | 101 | 1 | Alpha123 | 2.1 | ID7700-1222B |
| 2 | 101 | 1 | Alpha123 | 3.3 | ID701223A |
| 3 | 101 | 1 | Alpha123 | 3.2 | ID7700-1222B |
| 4 | 101 | 1 | Alpha123 | 4.0 | ID701223A |
Other¶
In [4]:
SHOW = False
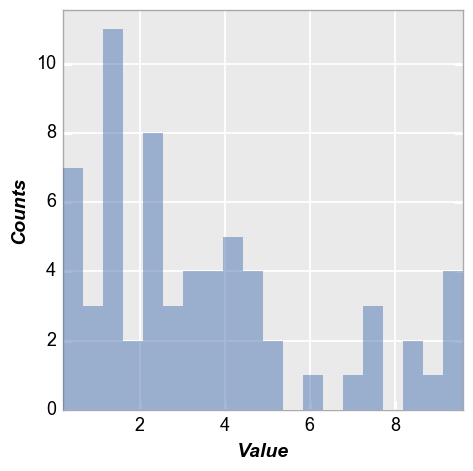
Simple histogram¶
Vertical bars¶
A simple histogram with default bin size of 20:
In [5]:
fcp.hist(df=df, x='Value', show=SHOW)
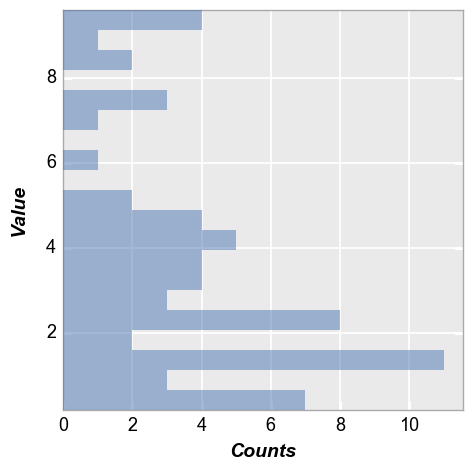
Horizontal bars¶
Same data as above but with histogram bars oriented horizontally:
In [6]:
fcp.hist(df=df, x='Value', show=SHOW, horizontal=True)
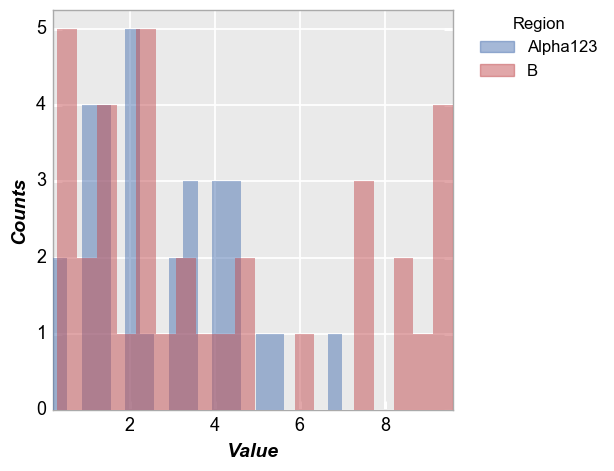
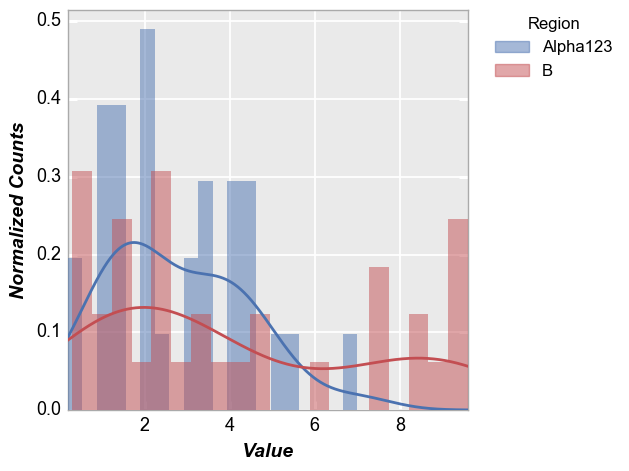
Kernal density estimator¶
In [8]:
fcp.hist(df=df, x='Value', show=SHOW, legend='Region', kde=True, kde_width=2)
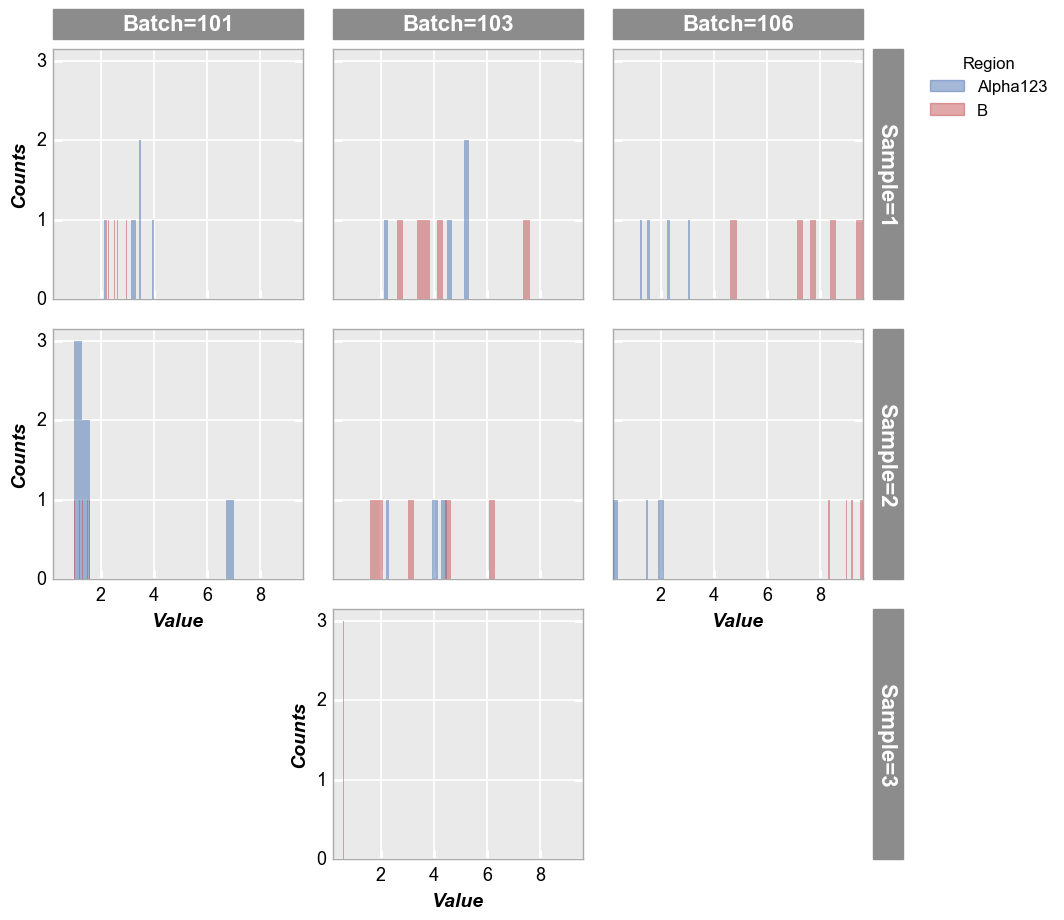
Row/column plot¶
Make multiple subplots with different row/column values:
In [9]:
fcp.hist(df=df, x='Value', show=SHOW, legend='Region', col='Batch', row='Sample', ax_size=[250, 250])
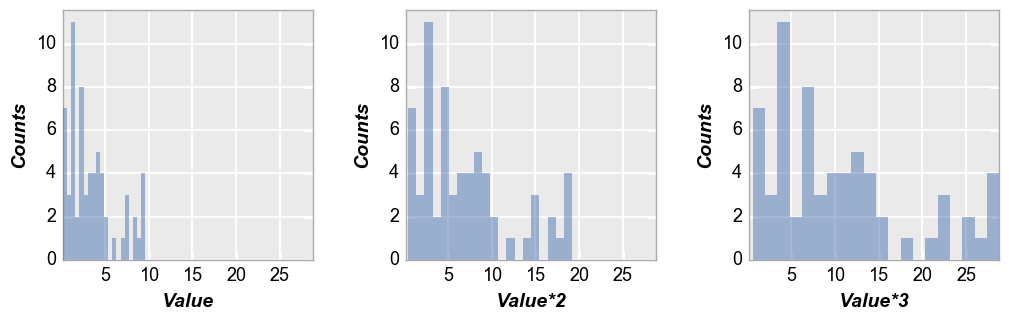
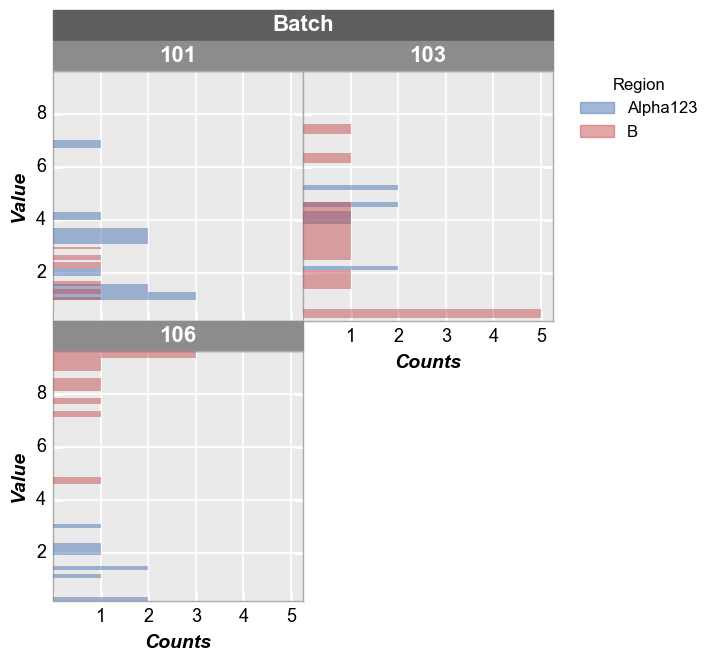
Wrap plot¶
By column values¶
In [10]:
fcp.hist(df=df, x='Value', show=SHOW, legend='Region', wrap='Batch', ax_size=[250, 250], horizontal=True)
By column names¶
In [11]:
df['Value*2'] = 2*df['Value']
df['Value*3'] = 3*df['Value']
fcp.hist(df=df, x=['Value', 'Value*2', 'Value*3'], wrap='x', show=SHOW, ncol=3, ax_size=[250, 250])